
Data engineering life cycle
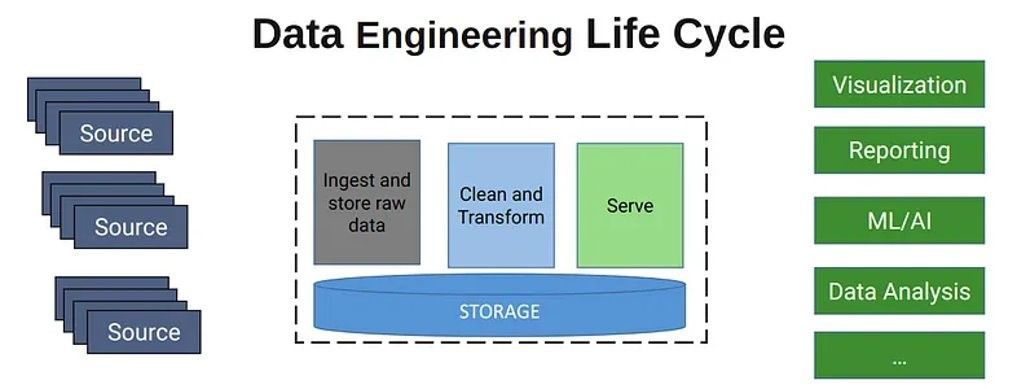
Data engineering is the practice of developing, implementing, and maintaining systems and processes to collect, clean, store, and prepare data for analysis, reporting, and other data-driven tasks. It focuses on ensuring that data is accurate, complete, and accessible to support various data-related activities within an organization.
Data engineering life cycle
- Data sources
When we talk about data sources we can say that we have a lot of options to take our data from:
- We can take the data from a file storage like csv, json, avro, binary etc.
- We could collect data from APIs. An API (Application Programming Interface) is a set of rules and protocols that allows different software applications to communicate and interact with each other. E.g. we could use API of youtube
- We could use NoSQL databases. NoSQL databases are flexible, scalable alternatives to traditional relational databases, ideal for handling diverse, unstructured data.
- We could use Web Scraping and scrape the data we need from specific web pages. For instance, we could scrape phone prices from amazon.com by using Selenium.
2. Data sources
When we talk about data sources we can say that we have a lot of options to take our data from:
- We can take the data from a file storage like csv, json, avro, binary etc.
- We could collect data from APIs. An API (Application Programming Interface) is a set of rules and protocols that allows different software applications to communicate and interact with each other. E.g. we could use API of youtube
- We could use NoSQL databases. NoSQL databases are flexible, scalable alternatives to traditional relational databases, ideal for handling diverse, unstructured data.
- We could use Web Scraping and scrape the data we need from specific web pages. For instance, we could scrape phone prices from amazon.com by using Selenium.
3. Data ingestion
Data ingestion is a crucial step in the field of data engineering that involves the process of collecting, importing, and transferring raw data from various sources into a storage or processing system where it can be analyzed, stored, and used for various purposes.
There are several types of ingestions:
- Batch Ingestion: Batch ingestion involves collecting and processing data in predefined batches or chunks at scheduled intervals. Data is typically collected over a period and ingested together. It is widely used at ETL (Extract, Transform, Load) processes.
- Streaming Ingestion: Streaming ingestion is a real-time or near-real-time process where data is ingested as it is generated, without waiting for predefined batches. Data is processed continuously as it arrives.
- Log-based Ingestion: Log-based ingestion involves capturing and processing log data generated by applications, servers, or devices. These logs are typically unstructured or semi-structured.
- Database Ingestion: Database ingestion involves extracting data from one or more databases, either in real-time or in batches, and transferring it to another database or data store.
- File-based Ingestion: File-based ingestion involves collecting data from various types of files, such as CSV, Excel, JSON, XML, or binary files, and importing them into a storage or processing system.
- API-based Ingestion: API-based ingestion involves retrieving data from external APIs (Application Programming Interfaces) provided by web services, cloud platforms, or third-party data providers.
- Web Scraping: Web scraping is the process of extracting data from websites or web pages, often in an automated manner, and ingesting it into a database or data store.
4. Cleaning and Transforming Data
Data cleaning and transformation are vital in data engineering because they ensure data accuracy, consistency, and readiness for analysis. They improve data quality, enable integration, enhance compliance, and optimize performance, ultimately leading to better insights and decisions.
There are countless options for data cleaning and transformation but most popular are:
- SQL (Structured Query Language): SQL is a powerful language used to interact with relational databases. It can be used for data cleaning tasks such as filtering, joining, aggregating, and transforming data within a database.
- Pandas (Python Library): Pandas is a Python library that provides data structures and functions for data manipulation and analysis. It is especially useful for data cleaning, transformation, and exploratory data analysis.
- Apache Spark: Apache Spark is a distributed data processing framework that includes libraries for data cleaning and transformation. Spark provides APIs in multiple languages (Scala, Python, Java) and is particularly suitable for big data cleaning and analysis.
- To have a good data flow, data transformations must be done according to a data model. A data model represents the way data relates to the real world. There are three types of Data Modeling: conceptual, logical and physical.
5. Data Serving
Data serving is a critical aspect of data engineering that focuses on making data accessible, available, and reliable for consumption by downstream applications, analytics, and end-users.
Data serving is essential for data engineers because it ensures that the data they manage is not just stored but also delivered efficiently and securely to meet the needs of business users, analysts, and applications.
Expected features of served data include trust (data reliability), accuracy (freedom from errors), the right format (compatibility with tools), the right schema (logical structure), the right granularity (level of detail), and meeting specified time requirements (SLA and latency). These features are vital for ensuring that users and applications can rely on the data for accurate decision-making, analysis, and seamless integration into their workflows.
Data Orchestration
Data orchestration in the context of data engineering refers to the process of coordinating and automating the flow and transformation of data between various systems, applications, and data sources. The tasks described until now can be automated through one workflow by using Data Orchestration tools.