
Snowflake has various tools and technologies that can be used for migration
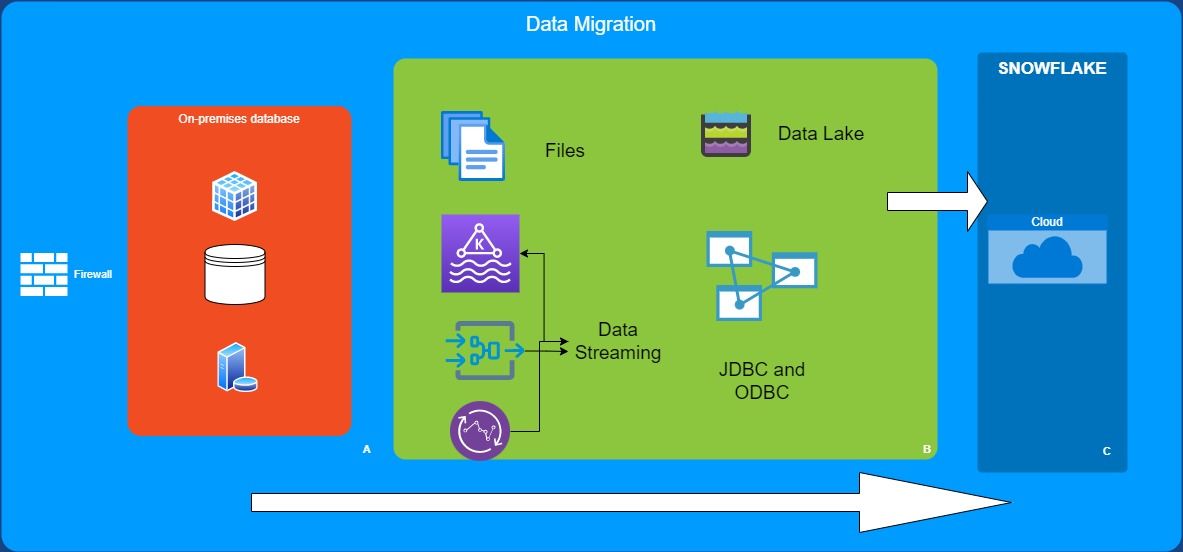
· Data File Loading: Which is the most common and highly efficient data loading method in Snowflake. This involves using SnowSQL to execute SQL commands to rapidly load data into a landing table. Using this technique it’s possible to quickly load terabytes of data, and this can be executed on a batch or micro-batch basis. Once the data files are held in a cloud stage (EG. S3 buckets), the COPY command can be used to load the data into Snowflake. For the majority of large volume batch data ingestion this is the most common method, and it’s normally good practice to size data files at around 100–250 megabytes of compressed data optionally breaking up very large data files were appropriate.
· Replication from on Premises Databases: Snowflake supports a range of data replication and ETL tools including HVR, Stitch, Fivetran and Qlik Replicate which will seamlessly replicate changes from operational or legacy warehouse systems with zero impact upon the source system. Equally there are a huge range of data integration tools which support Snowflake in addition to other database platforms and these can be used to extract and load data. Equally, some customers choose to write their own data extract routines and use the Data File Loading and COPY technique described above.
· Data Streaming: Options to stream data into Snowflake include using the Snowflake Kafka Connector to automatically ingest data directly from a Kafka topic as demonstrated by this video demonstration. Unlike the COPY command which needs a virtual warehouse, Snowpipe is an entirely serverless process, and Snowflake manages the operation entirely, scaling out the compute as needed. Equally, the option exists to simply trigger Snowpipe to automatically load data files when they arrive on cloud storage.
· Inserts using JDBC and ODBC: Although not the most efficient way to bulk load data into Snowflake (using COPY or Snowpipe is always faster and more efficient), the Snowflake JDBC and ODBC connectors are available in addition to a range of Connectors and Drivers including Python, Node.js and Go.
· Ingestion from a Data Lake: While Snowflake can be used to host a Data Lake, customers with an existing investment in a cloud data lake can make use of Snowflake External Tables to provide a transparent interface to data in the lake. From a Snowflake perspective, the data appears to be held in a read-only table, but the data is transparently read from the underlying files on cloud storage.
· Data Sharing: For customers with multiple Snowflake deployments, the Data Exchange provides a seamless way to share data across the globe. Using the underlying Snowflake Data Sharing technology, customers can query and join data in real time from multiple sources without the need to copy. Existing in-house data can also be enriched with additional attributes from externally sourced data using the Snowflake Data Marketplace.
Source: Medium Blog